Model failure is a huge concern for any AI-driven organization. The phenomenon that causes models to stop working in production—known as model drift, model degradation, or The Day 3 Problem—is a massive drain on resources.
Our recent blog post on model drift breaks down the details of this problem: what it is, why it happens, and how it ruins the utility of AI in production. But it doesn’t explain what to do about it.
You can’t prevent model drift—but you can overcome it. In fact, controlling and responding to model drift is essential for long-term success with AI.
So, how do you stop model drift from tanking your AI projects? You take the following steps:
- Identify model drift as soon as it occurs.
-
Retrain your models so they understand incoming data.
- Redeploy those models in hours—not weeks or months.
Together, these steps are known as model remediation—the key to unlocking sustained value from your AI program.

On the left, an object detection model in production has misidentified a street sign as a person. This situation calls for model remediation. By working through the process discussed below, users can rapidly retrain AI models to reduce errors—removing the wrong inference and delivering trustworthy object detections, as seen on the right.
What Is Model Remediation?
Model remediation is the process of restoring a failing AI model to good health and returning it to production. By starting remediation at the first sign of a problem, you stem the flow of bad inferences and—ultimately—get more effective uptime and return on investment (ROI) from your model.
On the surface, remediation seems simple: Catch a model drifting, retrain a new model, and then swap the new one for the old.
In reality, it’s more complicated. Many questions factor into each step of the process:
- How do you know if your models are drifting?
- If they are, how can you tell if they need rapid remediation?
- Where do you get the data to retrain them?
- How do you trust that a newly trained model will perform better than the old one?
Fortunately, a structured process and tooling can automate much of the work for model remediation, making it easier for data teams to get effective models back into production fast.
Key Takeaways:
- Model remediation is the process of fixing a broken AI model and returning it to production.
- It is instrumental to maximizing the ROI of your AI models.
- Although remediation is complicated, a streamlined process and tools can automate much of the remediation workflow.
Why Do Models Need Remediation?
Sooner or later, most AI models—91%, according to this Scientific Reports article—start to develop problems in production. Model remediation is simply the process of fixing those problems so that your model continues to work the way you want.
That said, not all AI models need remediation—at least not an emergency, “all hands on deck” approach to it. Drifting models may continue to perform well enough for your purposes, at least in the short term (such as recommendation engines for streaming services). Others may deliver inferences that are only valuable for a few seconds—object detection models used in self-driving cars, for example.
But models that produce critical, persistent, or time-sensitive outputs need to maintain the highest level of performance possible. AI models for high-speed trading, medical diagnostics, and national intelligence applications all need quick remediation to continue generating safe and trustworthy results.
|
Cause of Drift |
Definition |
Example |
|
Natural adaptations |
Data changes in response to outputs from an AI model. |
A financial trading model sells a stock because other models are selling it, driving down its price. |
|
Adversarial adaptations |
An agent’s behavior changes in order to evade an AI model. |
An enemy air force attaches tires to its airplanes to trick models trying to detect them. |
|
Use case differences |
An AI model that functions well in one context produces poor results in another. |
A model tracking US-China relations fails to interpret US-Japan relations correctly. |
|
Time sensitivities |
An AI model trained on data from earlier time periods misses new contextual changes. |
A model that understands US-Japan relations in the 1940s fails to produce useful insights for US-Japan relations today. |
|
Chaotic interference |
A change in an upstream AI model’s settings introduces inaccuracies into a downstream model. |
A change to an embedding model causes a text classification model using its outputs to label everything incorrectly. |
|
AI aging |
The process by which random variations in training can contribute to accelerated degradation. |
An effective object detection model simply starts to waver more and more in accuracy over time. |
Key Takeaways:
- AI models need remediation to restore their performance, which commonly degrades in real-world applications.
- Models that produce critical, persistent, and time-sensitive outputs (financial trading, medical diagnostics, national defense, etc.) need remediation to occur rapidly.
How Have Data Teams Remediated Models Until Now?
Until recently, most data teams lacked a standardized or streamlined process for model remediation. With so much emphasis on building and deploying models, remediation was often treated as an afterthought. When models did need fixing, the process involved a lot of manual coding and data curation that made it take longer than necessary.
But the increasing adoption of AI applications across business and government has created a need to keep models performant. With millions of dollars and lives on the line, enterprise leaders can no longer let their AI projects limp along or sit idle without a working model. Organizations now depend on this technology, and they have new expectations and standards of quality that require effective models—which means they need a process for remediating their models when they inevitably start to struggle.
Key Takeaways:
- Data teams have long treated AI post-production—including model remediation—as an afterthought.
- Widespread adoption of enterprise AI has made model remediation a high priority for data teams.
What Steps Are Involved in Model Remediation?
Once an AI model goes live, one of three things can happen.
- The model continues to perform well forever.
- Drift degrades the model’s performance over time.
- The model fails right off the bat.
Automated monitoring tools can identify when model drift starts to occur. (At Striveworks, we use statistical tests to determine whether or not a model is experiencing drift. Read about our drift detection here.)
When monitoring detects drift and data teams decide the predictions are not sufficiently accurate, they need to kick off a remediation workflow.
Model remediation consists of a five-step process:
- Evaluate the data: Determine if the problem is caused by your data or your model.
- Curate a dataset: If your model needs attention, source training data that more closely matches the data your model is seeing in production.
- Train a model: Use your new training data to fine-tune your existing model—a process that’s much faster than training a new model from the ground up.
- Evaluate the model: Test your new model version to confirm that it exhibits appropriate performance.
- Redeploy the model: Push your remediated model back into production.
Carrying out each of these steps manually takes days or weeks of effort—if you can do them at all. Tools that support these steps—automatically creating a training set from production data or centralizing evaluations in a persistent, queryable evaluation store—enable data teams to take a production model from inadequate to exceptional in a matter of hours.

Model post-production starts with an automated process for detecting drift occurring on ML models. Two standard multidimensional tests—Kolmogorov-Smirnov and Cramér-von Mises—are widely used to confirm whether production data is out of distribution with models’ training data. If the incoming data falls below critical thresholds, a data team then intervenes to evaluate if, indeed, model drift is underway. If so, teams need a new, more applicable dataset to fine-tune their model—a process that takes notably less time than training a new model. Remediated models are then re-evaluated for efficacy and redeployed into production, where the cycle begins again.
Key Takeaways:
- Automated monitoring can detect when a model stops working.
- Manual model remediation can take days or weeks of effort.
- Tooling that supports key remediation steps, like evaluation and dataset curation and model fine-tuning, can cut that time to a matter of hours.
How Do I Tell If the Problem Is With My Data or My Model?
When you detect drift happening to your AI models, two important questions crop up:
- Is the problem with your data pipelines?
- Is the problem with the model itself?
Both data and model problems can lead to model drift. The first step in the model remediation process—evaluate the data—is to figure out which problem you’re having.
Fixing Problems With Data Pipelines
If your problem resides in your data, fixing it can pose a challenge. Problems with data can take many forms and can come from anywhere in your machine learning operations (MLOps) workflow:
- Maybe all your training data was inappropriate for your use case
- Maybe some segments of your dataset worked great, but they were thinner than expected (resulting in overfitting)
- Maybe your data was appropriate, but its resolution (in the case of a computer vision model) was too low to work for incoming data
- Maybe an upstream model changed and it now transforms your data in a completely different way
- Maybe you’re dealing with a combination of these issues
For the best chance at solving a data problem, you really need an unobstructed view into your data lineage. If you have auditability over your data, you can comb through it and search for anomalies or errors—mislabeled datums or upstream data sources with new parameters. Then, you can apply a point solution to the specific issue—like sourcing new training data or patching an API.
Unfortunately, data auditability is still immature in most machine learning workflows. Data teams can often examine part of their data pipeline but not all of it—especially with deep learning models that tend to operate like black boxes. Even to get that basic understanding of data, engineers typically need to alter their software or write a lot of custom code, especially when their workflows involve calls to external data services. That process just isn’t scalable.
“Custom coding for data lineage is simply insufficient,” says Jim Rebesco, Co-Founder and CEO of Striveworks. “Today, any organization can ensure that their AI-powered workflows have automated processes that can alert nontechnical users to identify, confirm, and report errors.”
Fortunately, standards are starting to change. Striveworks, for instance, has developed a patented process that gives engineers access to their full data lineage, including calls to external services. (Read all about our data lineage process here.)
Fixing Problems With Models
Compared to fixing data pipeline problems, fixing models appears straightforward: You retrain your current model or replace it with a new one. But it’s more complex than it seems.
What caused the problem with your model? Did your incoming production data move out of distribution with the model’s training data (i.e., did the data drift?)? Or did its use case shift and render the results of your model inadequate (i.e., was it concept drift?)?
According to Daniel Vela and his coauthors in their 2022 Scientific Reports article, “Retraining a model on a regular basis looks like the most obvious remedy to [model drift], but this is only simple in theory. To make retraining practically feasible, one needs to, at least:
- develop a trigger to signal when the model must be retrained;
- develop an efficient and robust mechanism for automatic model retraining; and
- have constant access to the most recent ground truth.”
Automated monitoring serves as that initial trigger, letting data teams know when models need retraining. Deploying a ready-to-go model is as simple as loading it onto the inference server and connecting any APIs.
But if you don’t have a better model ready, you need to train one on data that’s more appropriate for your actual use case. Finding that data is tricky. If you had better data, you probably would have used it to train your model in the first place.
Of course, if you had a model in production, you do have better data: your production data itself. You just need to have captured it for use in creating a new training dataset. Not all MLOps platforms support the persistent inference storage needed (although Striveworks does). But using the data from your actual model in production is still your best bet for updating your model into one that works for your use case.
Fortunately, you don’t have to start from scratch. Your current model is often still a viable option—it just needs some adjustment. Retraining your model on a new dataset takes much less time than training a whole new model. You already have model weights loosely dialed in. Your model really just needs fine-tuning to improve it for your specific use case. Instead of processing 100,000 new data points, you can zip through a highly relevant dataset—improving its performance in a few hours, instead of the several days it may take to train a brand new model.
Key Takeaways:
- If your model is drifting, you either have a problem with your data or a problem with your model.
- Problems with data are often difficult to identify; access to data lineage is vital.
- Problems with models are resolved by replacing the model with a new one.
- Using your own production data is a great way to curate a dataset that works ideally for your use case.
- Retraining an existing model is much faster than training a wholly new model.
How Do I Know My New Model Will Work Better Than My Old Model?
After you retrain your model, data teams need to reevaluate it to confirm that it is better tuned to handle your production data. Even if you are using a world-class dataset, problems can arise during training.
“When remediating, you want to ask some hard questions,” says Rebesco. “Is this model better than the old one? Will it continue to be better? What are its failure modes? Is there an ability to evaluate and compare the models with other ones?”
Maybe your model responds well to most segments of your data but not all. Maybe you selected a set of hyperparameters that resulted in an overall worse model. The only way to make sure your model will perform well is to evaluate it.
Historically, data teams would often evaluate their models ad hoc—running an evaluation in a Jupyter Notebook and saving the results in an email, Slack thread, or Confluence page. Obviously, this process doesn’t scale. But new tools are now coming online to support the model remediation workflow with standardized, centralized model evaluations. Striveworks’ Valor is an open-source option available on our GitHub that streamlines evaluations as part of your AI workflow. Teams can use it to easily compare the suitability of their remediated model versus other models and to check that their new model is better aligned with their production data.
Key Takeaways:
- You need to reevaluate your model after retraining to confirm that it will work better.
- A centralized evaluation service like Striveworks’ open-source tool, Valor, lets you evaluate models consistently at scale.
Model Remediation Is the Next Link in the MLOps Value Chain
It may help to think of model remediation as the next step in the MLOps value chain.
“In the MLOps space, everybody has been saying, ‘You can build and deploy models.’ Of course that’s valuable, but even the language people are using is wrong,” says Eric Korman, Co-Founder and Chief Science Officer of Striveworks. “They need to think about the full life cycle of a machine learning model—build, deploy, and maintain.”
Before now, data teams would stop after getting a model into production. The standard workflow involved the following steps:
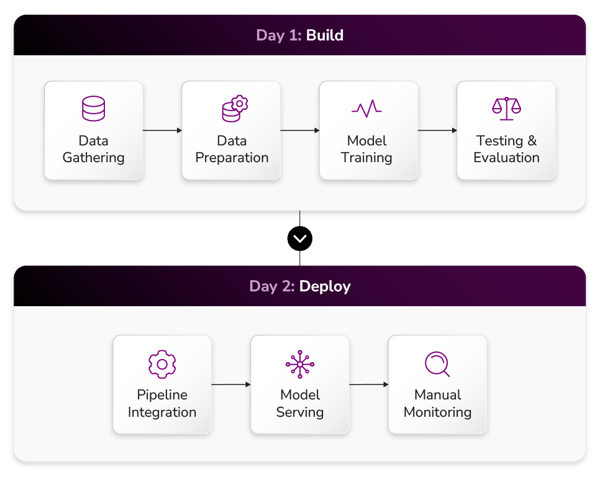
But that process has left a lot of AI models breaking in production—and a lot of data teams left holding the bag. Model remediation completes the real life cycle of AI models, taking them through degraded performance and back out again.
It also lets organizations respond to the shifting value center of MLOps. The greatest value from AI no longer comes from putting more and more models into production; the opportunities for value generation come from keeping those models performant longer, which enables AI to become a trusted part of your tech stack. Model remediation is the process that makes it happen.
***
Frequently Asked Questions
- What is model remediation?
Model remediation is the process of restoring a failing AI model to good health and returning it to production. It is a necessary step in getting long-term value from AI models.
- Why do AI models need remediation?
91% of AI models degrade over time. To make them work effectively again, data teams need to diagnose the reason behind that degradation, retrain their models, reevaluate them to confirm effectiveness, and redeploy them. That process is model remediation.
- How do I remediate a failing AI model?
To remediate a failing AI model, you need to follow this five-step process:
- Determine if the cause of your model failure is your data or your model.
- If your model needs attention, source training data that more closely matches the data your model is seeing in production.
- Use your new training data to fine-tune your existing model—a process that’s much faster than training a new model from the ground up.
- Test your new model version to confirm that it exhibits appropriate performance.
- Push your remediated model back into production.
With enough time and resources, data teams can execute these steps manually—but an MLOps platform makes the process faster and scalable.
- What happens if I don’t remediate my AI model?
Certain AI models don’t need rapid remediation because their inferences are nonessential or transient. However, AI models that are used in critical workflows for medical diagnostics, high-speed trading, national defense, and other consequential scenarios need to remain high-functioning as consistently as possible. Without remediation, these models deliver wrong inferences that lead to bad or even catastrophic outcomes.
