Once you train a machine learning model effectively, it has the ability to perform incredibly useful tasks, like detecting objects on real-time video, summarizing huge documents, and even predicting the likelihood of wildfires.
.png?width=600&height=314&name=202405-B-WhyWhenHowRetrainMLModels-Hero%20(1).png)
Unfortunately, the useful lifespan of many trained models is very short, which is one reason that the majority of trained models never make it into production—and why AI initiatives fail to reach maturity. These limitations raise important questions:
- Why do so many models have such a short lifespan?
- What causes model degradation?
- How can you detect when a model is no longer functioning properly?
- And, most importantly, how do you resuscitate a failing model?
Let’s explore the reasons why so many organizations find themselves with models that fail—and how we can use the Striveworks platform to ensure that models remain relevant.
Why Do Machine Learning Models Need Retraining?
Once trained, most models are static.
For models to adapt, they need feedback. To train—and to get better at the thing it is trying to do—the model has to know if the output it generated was the right thing.
An AI model playing a game can determine whether or not it won, which gives it feedback. A model predicting the rest of the word you are typing gets feedback when you finish that word and move on.
But an AI model that is detecting people in a security camera has no way to know if it missed someone or if it thought the mannequin in the background was actually a person. There’s no automatic feedback mechanism.
However, while models are generally static, the world around them is constantly evolving. Sooner or later, data from the real world looks very different from the data used in the model’s training. Any model’s performance will be poor (or, at best, occasionally lucky) when the data it is ingesting is significantly different from the data on which it was trained. As a result, the model’s performance—its correctness—degrades. This is commonly known as model drift. If the operating environment evolves very fast, that drift can happen in days—or even hours.
At Striveworks, we call this the Day 3 Problem:
- On Day One, your team builds a model.
- On Day Two, you put that model into production.
- On Day Three, that model fails and you’re left to deal with the aftermath.
When a previously effective model performs poorly on current data, the solution is always the same: Retrain or fine-tune the model using that same current data.
Below, we illustrate a few scenarios in which model drift can negatively impact model performance. These examples focus on computer vision models, but the same issues occur with natural language processing models, tabular classification models, and every other domain.
Example 1: Facial Recognition Systematically Failing for People of Color
It has been widely reported that early systems for facial recognition failed dramatically on people with darker skin tones.
In the early days of facial recognition, the problem was that all (or nearly all) of the training data used to build the facial recognition systems consisted of white faces.
In effect, the world the model saw, because of its training, consisted only of white people. Obviously, the world in which the model was deployed looked very different.
In this case, the real world didn’t change. However, the model still needed retraining because of the discrepancy between training data and the data the model encountered in production.
Example 2: Seasonality Changing the Natural Environment
Let’s suppose you want to use a model to identify building footprints, roadways, and waterways in the United States from satellite imagery.
To train your model, you collect recent sample imagery from each state and then diligently label all the collected imagery. This effort gets you a good representation of built features across the country.
Although the model may initially work very well, as summer turns to fall or fall turns to winter, the image characteristics change significantly.
Since the training data was all recent, it all came from the same season. While it is true that spring in Alaska looks quite different from spring in Texas, a change in the seasons will still cause a significant shift in the makeup of the imagery. The images could have more green or brown in warmer months and more white in colder months. The majority of water may be frozen in January but liquid (or even evaporated) by August.
Each of these factors alone could impact a model. All of them together will almost certainly produce negative effects.
Example 3: New Vehicles on the Roads
Consider a model that is monitoring vehicles in a parking lot. One of its tasks is to classify vehicles by their make and model.
Let’s assume your AI model is well trained on imagery provided by your cameras over a reasonable time period. It performs well.
Because every year there are new makes or models of vehicles on the road, your model will eventually start to see vehicles that weren’t included in its training data. Over time, vehicles that didn’t exist when the training data was collected will start to visit the parking lot.
If the new vehicles are similar enough to old vehicles, then your model will likely continue to correctly identify them. But in the case of a brand new make or model, your neural network may not even have the “language” required to provide a correct response.
Until the machine learning model is retrained with an expanded vocabulary, it will make wrong identifications when encountering these new vehicles—consistently confusing them with a vehicle already in its vocabulary.
Example 4: New Sensors Altering Imagery
What if you have a model trained to recognize people in your security camera feed?
In this scenario, the model is well trained on imagery taken directly from the camera over a long period of time (e.g., in varying weather, seasons, congestion, etc.)
After some time, the security camera receives an upgrade to a much higher resolution camera.
Intuitively, you may expect that the model would perform better with sharper, clearer imagery. But the reality is that the model will likely perform worse.
Again, the reason is that image characteristics have significantly changed. Many parameters change with new cameras, including the perceived size of the people in the image. The model may have learned that people are typically 30 pixels wide and 100 pixels tall. This learned feature, along with others operating under this assumption, served the model well with the original camera resolution. But the new model’s resolution is at least twice that of the original camera. As a result, people are now typically 60 pixels wide and 200 pixels tall—or more, if the resolution is even higher.
With this higher resolution, all the model’s internal learning about what a person looks like is wrong. As a result, the model will almost certainly make many mistakes.
When Do Machine Learning Models Need Retraining?
The short answer to this question is obvious: When a machine learning model no longer performs well enough, it needs retraining. And, of course, “well enough” depends on the user and the use case.
But the follow-up is more serious: How do we know when a model isn’t performing well? Keep in mind: When a model is in production, there are usually no ground truth labels we can use to measure our model’s output.
One option is to simply require human-in-the-loop monitoring of a model’s output, say, by randomly sampling inference outputs, supplying a correct label (model output), and scoring the model against the human-assigned labels.
But this method is labor intensive and slow—by the time problems are detected, a bad model may have been in use for some time. It is much better to take poorly performing models out of production before they cause too much damage.
Yet, there is a second answer to our original question that is less obvious—but it lends itself to fully autonomous monitoring.
When do machine learning models need retraining? When you no longer trust the model.
Trust in a model can and should erode quickly when we apply the model to data that is unlike its training data. Fortunately, there are a variety of ways to automatically determine if new data that a model is seeing is similar to the model’s training data. Out-of-distribution (OOD) detection algorithms can show us if new data is similar enough to old data.
Out-of-Distribution (OOD) Detection With the Striveworks MLOps Platform
In the Striveworks MLOps platform, OOD detection begins with a characterization of the dataset.
Figure 1 illustrates the process of characterization.
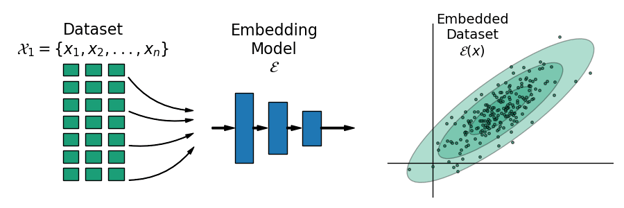
First, we take a dataset and use a generic neural network embedding model to generate low-dimensional representations of each datum (i.e., each image).
Think of these embeddings as just a vector or a list of numbers.
Figure 1 illustrates these embeddings as two dimensional vectors: x-y coordinates.
With our collection of embedding vectors in hand, it is a straightforward process to statistically describe them by computing their sample mean and covariance.
The mean and covariance characterize our data by a statistical distribution. One of the things you’re likely to learn in an introductory statistics course is that 75% of the data points in a dataset are within two standard deviations of the mean, 89% of the data are within three standard deviations, etc. (These numbers are true for any dataset, regardless of distribution. Percentages are even higher if the data is normally distributed.)
This implies that it is rare for data to be a large number of standard deviations away from the mean.
If you observe a single point that is, say, five standard deviations away from the mean, that is rare, but not necessarily shocking—roughly 4% of the dataset could be that far. However, if you start to observe many points that are five or more standard deviations away from the mean, then you can trust that at least some of these new points are from a different data distribution than your training data. They are “out of distribution.”
Using the mean and covariance calculated above, we can compute the Mahalanobis distance between our training dataset and any new data via that new data’s embeddings. This gets used instead of standard deviation when the data has more than one dimension.
Of course, there is nothing special about five standard deviations or a particular Mahalanobis distance. Rather, a data science practitioner must decide the exact distance at which data points are surprising enough to be called OOD.
In addition to identifying individual data points that are far from the training distribution, the Striveworks MLOps platform allows users to check whether an entire data stream being passed to a model has drifted from that model’s training distribution. Along with aggregating the OOD detection scores discussed above, we also apply a few classical tests from non-parametric statistics to the inference data stream. As in the case of OOD detection, we use a neural network model to compute embeddings for both the training and inference data, and then we apply the multidimensional Kolmogorov-Smirnov and Cramér-von Mises tests to check for model drift. These tests use two different criteria for measuring the distance between the cumulative distribution functions of the training and inference data.
How Do I Retrain a Machine Learning Model?
The mechanics of retraining a machine learning model are (nearly) the same as those used when initially training the model. But this time, we have a model in hand that already performs well on relevant data.
Model training (or retraining) always starts from some set of weights.
Those weights may be chosen randomly from some statistical distribution. This is what happens if this model has never before been trained. Alternatively, weights may come seeded from a previous training of a model if and when they are available. In some cases, weights may come from a training of the model on a completely different dataset. For example, for computer vision models, it’s common to use “pre-trained” weights resulting from training on the ImageNet dataset. When this happens, we generally don’t consider it to be retraining a model. Instead, we consider this a case of transfer learning.
Model retraining relies on a good seed—the initialization of the weights from the original model training.
Having good initial weights for retraining allows the process to run much faster than the initial, from-scratch training of the model. This is because we are essentially starting out with a 90% solved problem and just looking to improve at the margins.
When retraining a machine learning model, the single most critical component is the curation of the dataset. We cannot simply resume training on the original dataset and expect to get better performance on the new, OOD data because the training set, not the model being trained, dictates what is in- or out-of-distribution. If the dataset doesn’t change, the distribution hasn’t changed, and OOD data is still OOD—you can’t feed the model more examples of dogs and expect it to learn to recognize cats.
It is therefore essential to include recent, novel data in the new dataset for retraining.
Because this data is novel and OOD with the original training data, we need a human to help annotate it prior to training.
There are still big questions outstanding, though: Should you include the original dataset in the new training data? What ratio of novel OOD data to original data should you maintain?
In many cases, it will be beneficial to include the original data and simply augment it with some novel data. These are cases when the real-world data has expanded in scope, rather than changed.
Consider the first example above that discussed facial recognition. To solve the lack of representation, it wouldn’t make sense to replace all the white faces with non-white faces. That would simply skew the model in a different, wrong direction. Instead, the distribution needs expansion to include both.
In other cases, there may be multiple viable routes to good results. With seasonal changes (e.g., the second example above), we expect the data to eventually return to the original distribution—but most or all of the current data may be different from the original training data. In this case, we can try to build a single model that can operate in both conditions. To do so, we’d want to augment the initial training data to include new seasonal data. Or, we could build a small collection of specialized models—each one only operating on in-season data—and swap them in or out as seasons change. Here, we would want to have distinct training datasets for each season. New data would become its own dataset.
If the world has fundamentally changed and will not return to the old normal (e.g., Example 4 above with new sensors collecting data), then it no longer makes sense to include the old data in our new dataset.
What Tools Does Striveworks Have to Help?
The Striveworks MLOps platform is centered on postproduction machine learning: monitoring, evaluating, and retraining machine learning models back to good performance.
When you first register a dataset in the platform, an alert triggers a statistical analysis of the dataset.
The resulting characterization (mean, covariance, etc.) is stored and associated with the dataset. This information is used to recommend models that may work well for the dataset. It also forms a useful starting point for training a new model and recognizing OOD data.

If a model is trained on a registered dataset, then we can automate drift detection on the model while it is in production. The Striveworks MLOps platform has several options for assessing drift, including semantic monitoring, the Kolmogorov-Smirnov test, and the Cramér-von Mises test. Each option characterizes model inputs as either in distribution or OOD, flagging the associated inference to inform whether or not drift has been detected.

If the user observes enough OOD data, they need to take action.
First, as discussed above, is curating improved, more current data. Striveworks users can easily load new datasets or choose a registered dataset from their existing catalog.
However, the most useful data for retraining is already stored on the platform. The Striveworks inference store captures every output generated by your production models. When you receive an alert that your production data is OOD with a model’s training data, you can explore this inference store to confirm or refute any errors in prediction. If your data has indeed drifted away from your model’s training set, you fortunately have a ready-made collection of specific, current data on which to retrain your machine learning model. You just need to annotate it.
(The Striveworks MLOps platform also provides a utility to assist these annotations.)
Using a pre-trained model to assist with annotations has many benefits. For current data where the model is already good, a human only needs to verify that the annotation is correct—usually, this is very fast. This process allows human annotators to focus their attention on data where the model is failing, concentrating effort where it is most needed. The platform also allows models to be trained as annotations occur, improving annotation hints over time. This feature is very effective for fine-tuning the model.
After enough current data has been annotated, it is a simple matter to retrain the model. Striveworks users can get a headstart, using our training wizard to fine-tune models in their catalog.

Evaluating Retrained Models
Once you have retrained your model, it should be ready to redeploy into production. But not every retraining run is created equal. Certain training data or hyperparameters can produce more effective models for your use case than others. So, before you spin up another inference server, the best practice is to conduct an evaluation on your retrained model. Evaluations let you test whether or not the retraining dataset and settings were truly appropriate to address your issue in production. They also provide quantifiable metrics for performance by checking whether or not a dataset falls within distribution for your retrained model.
Depending on their training, models may not generalize well to fine differences and, therefore, may exhibit performance bias—performing better on one subset of data than another. Pre-deployment evaluations expose instances of performance bias before models return to production, letting you further tweak your models to ensure that they produce trustworthy results.
Striveworks users can evaluate their models using the platform’s built-in evaluation service. (Check out our open-source evaluation service, Valor, on GitHub). Compare metadata and evaluation metrics for models trained on the same dataset and for a single model across datasets. The goal is to better understand expected model performance across a full dataset, plus changes in performance based on fine differences in data segments.
Preparing for Next Time
Of course, the unfortunate truth is that even those trustworthy models only last so long. Redeploying your model is as simple as spinning down your old inference server and spinning up a new one—but as soon as you do, the clock starts ticking until your model needs retraining.
Consider how you want to manage these repetitive cycles. If your number of models or urgency is low (or if you have an abundance of time), you can likely remediate by hand. But for managing multiple models, especially those in real-time operations, consider an MLOps platform designed for your model and data types.
Look for a platform with established infrastructure and standardized processes for managing monitoring, datasets, inferences, annotation, evaluation, retraining, and so on. Activity, versioning, and data lineage should all be centralized, making it easy to execute the tasks associated with model remediation in a consistent way at scale—instead of needing to search through Slack or Confluence for information or rebuilding infrastructure from scratch each time you need to update a model.
The Striveworks Platform Is a Workstation for Retraining Machine Learning Models
It’s important to remember that models perform best on data that is most similar to their training data. But a static dataset is a snapshot in time and, eventually, current production data will not look like the model’s original training data because the world is constantly changing. When this happens, the model will likely perform poorly. At a minimum, the model will no longer be trustworthy.
It is essential to remove bad models from production as quickly as possible when they are no longer trustworthy—before the model leads to bad decisions or outcomes. The Striveworks MLOps platform provides tooling to quickly recognize a shift in data and the accompanying loss of trust in a model, making it as easy as possible to retrain or update that machine learning model and get it back into production. Automated drift detection monitors production inferences for OOD data to alert users to the need to retrain. The inference store saves all model outputs, creating a highly appropriate, turnkey dataset for fine-tuning. Model-assisted annotation pipelines speed labeling along, and a persistent model catalog makes it easy to check out or reshelve models as needed and as appropriate. The Valor evaluation service ensures you deploy retrained models that are effective for your production data.
Ultimately, the platform serves as a complete workstation for model remediation, keeping models in production and generating value longer.
Want to know more about when and how to retrain machine learning models? Request a live demo of the Striveworks MLOps platform.
