This blog post is part of a series on geospatial analysis. View the other posts here:
Geospatial analysis has revolutionized multiple industries since it first gained commercial use in the 1990s. Now, mining, firefighting, defense, and even finance organizations rely on geospatial data every day to understand factors that affect them and to develop plans for operation.
In many cases, geodata gives organizations abilities that are otherwise impossible—such as observing foreign oil reserves and tracking the types of aircraft on airfields.
But even powerful tools and methodologies come with challenges. Geospatial data can bring huge advantages to organizations that use it effectively. Without the right tools, though, it can take serious resources—geographic information system (GIS) experts, training, and time—to produce useful results. There’s a lot more to it than just capturing satellite imagery.
Today, let’s explore the top challenges with geospatial analysis that organizations encounter when they try to apply it to improve their operations.
The Biggest Challenge: Too Much Data
Ironically, the biggest challenge that organizations face with making use of geospatial data is the sheer volume of it: There’s just too much to process.
While geospatial data was hard to come by 20 years ago, it’s now widely available for anyone with an internet connection. Google offers huge quantities of geospatial data for free through its Google Maps and Google Earth products. Commercial satellite imagery is easily accessible from industry leaders like Esri, Maxar, Planet, and Capella Space. Smartphone GPS data is also readily available to purchase. The challenge no longer lies in accessing data—but in making sense of it all.
‘They always say, ‘We're getting more pixels, but we’re not getting more people.’’
— Brett Foreman, Capella Space
The military is uniquely adept at processing and analyzing geodata, but even they struggle with the amount they capture.
“Where there are conflicts, the military needs as many observations as possible, in as much detail as possible, to be able to understand what’s happening on the ground,” said Brett Foreman, Senior Product Manager at Capella Space, an industry-leading synthetic aperture radar (SAR) data provider. It takes considerable time and effort to explore all that high-resolution imagery for points of interest, though.

“They always say, ‘We’re getting more pixels, but we’re not getting more people,’” said Foreman. Fortunately, machine learning has emerged as an effective tool for easing the burden of geospatial analysis. While human eyes have limited capacity to review imagery and identify interesting patterns or anomalies, computer vision models can sift through data with ease.
Object detection models can easily scour imagery to find every instance of an object. For the military, that may mean boats or airplanes. For civilian purposes, machine learning models could find trees in a plantation to support yield forecasting for agriculture or they could find every house over 1,500 square feet in a suburb to aid in city planning.
Change detection algorithms work wonders too. Even the best analysts fatigue when looking through thousands of nearly identical images, hoping to spot a critical difference. A machine learning model trained to identify changes can quickly search through the same dataset, tipping analysts to notable differences. The technology can reduce the time and effort from hours or days to minutes.
Data Complexity Is Another Huge Hurdle
Volume isn’t the only challenge with applying geospatial data, of course. In some cases, organizations have trouble working with the types of data and outputs involved.
Good, high-resolution imagery like that prepared by Capella Space and Maxar is huge. The size of a single image can run into the gigabytes, making these files difficult to transfer, which creates a burden to using them—especially when needed for rapid or real-time analysis.
“California has wildfires all the time,” said Foreman. “The incident commanders for the large wildfires, they’re publishing maps every 12 hours to show ‘Where is the fire?’, ‘Where are all my firefighting assets?’, or ‘What new areas have been evacuated?’ That data is published in map form. To create those maps it involves talking to people on the phone and analysts looking at imagery. The translation of that raw data into something usable for the public sector is really important because they have fewer people to do that analysis.”
Geospatial data is also more complex than other data types, such as text or tabular numbers. Beyond the raw pixels involved in each image, geospatial imagery includes complex structures and relationships that make it difficult to analyze.
For example, two points on a map that appear close in absolute distance may not be connected by a road network. Without that roadway, transportation between those points suffers even if they are only a few hundred meters apart. This barrier to navigation may have huge consequences for companies building offices or stores, logistics companies shipping orders, or militaries planning defense patrols. Similarly, two nearby points may fall within two different boundaries—national borders, county lines, or other legal jurisdictions. These nuances may not show up in imagery alone, adding complications to its use.
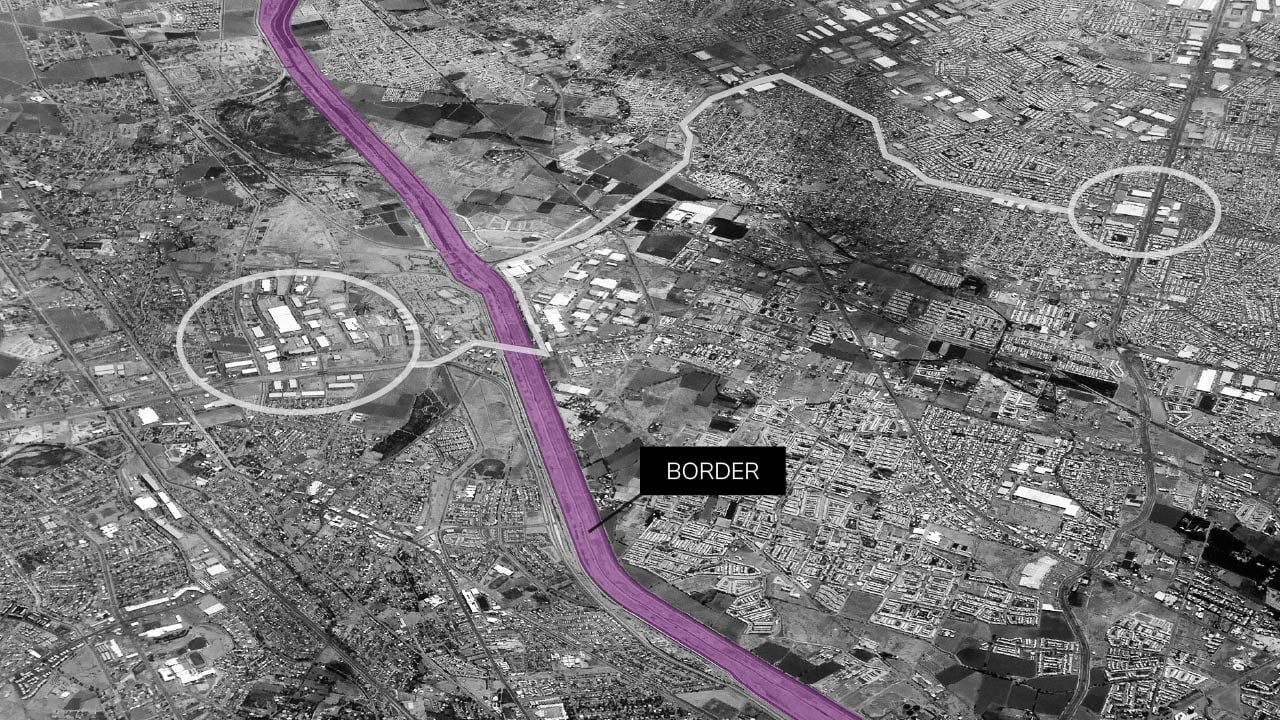
Geospatial data can reflect complex relationships about features in the world that may not appear obvious, such as international borders separating densely populated areas.
Moreover, geospatial data is also noisy. The image acquisition process introduces noise as it transforms optical signals into electrical signals, distorting the image and leading to false correlations, inaccurate assessments, and other errors in analysis.
Machine learning is invaluable for working through these data complexities. Models trained to identify specific objects of interest can process huge files, merge it with other data, and deliver relevant details quickly—getting the right information to the right people at the right time.
Models can also help clean datasets. Clustering algorithms can determine if certain pixels make sense within their context, identifying and removing noise to improve the data quality for further analysis. More advanced processes use convolutional neural networks to reduce noise and improve image fidelity.
Resourcing Is a Root Cause of Challenges
Of course, organizations could resolve many of the issues with geospatial data volume and complexity if they had enough resources. Huge teams of analysts can collect appropriate geospatial data, interpret it, and put it to good use.
But what organization has enough resources?
The National Geospatial-Intelligence Agency has thousands of experts with advanced skills in geospatial analysis, and they still look to technology to strengthen their output. Other organizations, such as local governments, may only have a small GIS team to process and deliver information in life-threatening situations, such as fires. In all cases, urgent scenarios demand a level of data processing that overwhelms even the most skilled analysts.
Machine learning can transform these scenarios—but it only helps if someone knows how to use it. Preparing datasets, training models, and applying them to target data can require a high degree of data-savviness and strong coding skills. Organizations can hire data scientists, but then they run into a different kind of resourcing issue.
Fortunately, no-code machine learning operations (MLOps) platforms, such as Striveworks, are now available. This technology allows non-specialists to ingest geospatial datasets, train sophisticated machine learning models, and deploy models with new data to scale up and dial in insights. Tools like these allow resource-strapped organizations to conduct advanced geospatial analysis—even if GIS or data science skills are in short supply.
Machine Learning Fixes Challenges—But Presents New Ones
Machine learning isn’t a quick and easy fix for challenges with geospatial analysis, though. One of the unfortunate truths about machine learning is that, sooner or later, models stop working.
Scenarios change, data changes, and a model that delivered great insights yesterday begins to produce wrong inference after wrong inference. Even though machine learning can solve other challenges with geospatial analysis, it introduces this problem of consistency. The only way to resolve failing models is through remediation—the process of fixing a broken model and getting it back into production.
Striveworks has made remediation a focus of our platform, enabling users to retrain and redeploy failing models in hours instead of days or weeks. But remediation is only one part of ensuring your models deliver good insights.
Before your model stopped performing, it delivered a series of wrong inferences. These outputs raise a lot of questions:
- What outputs did the model get wrong?
- How many?
- How long has this model been failing?
- How do we get the model performing well again?
- How long will it take?
- What wrong insights did we use to make decisions?
To answer these questions, auditability is critical. Users need to understand exactly which results from their models were wrong, when those problems started, and what steps they must take to fix them. Unfortunately, getting this information can prove challenging. Many AI systems function like a black box—users know the inputs and outputs, but the process in between remains a mystery.
Striveworks takes a different approach, though. Our patented data lineage process allows full transparency over your entire data workflow so that you can audit each step and confirm the integrity of your data, inferences, and the decisions that came from them.
This data lineage process is key to making the most of machine learning for geospatial and other data. By auditing your workflow, you can find the point where your model started to struggle and then track it to see all the other factors affected by its insights. Remediation will get your model back into action, but auditing ensures you can clean up any mess it made along the way.
Better Tools Make Geospatial Analysis Effective
Geospatial analysis is a boon to many organizations if they can overcome the hurdles involved in putting it to use. Data volume, data complexity, and a lack of resources are all big challenges with geospatial analysis that prevent companies from using their data effectively.
‘That’s why companies like Striveworks exist—because end users want to be empowered to make their own models, so they can run custom analyses to achieve their objectives.’
— Brett Foreman, Capella Space
Machine learning helps. By rapidly processing huge volumes of complex data, machine learning models take the strain away from analysts and put it on algorithms. Yet, machine learning introduces a challenge of its own: the difficulty of using a code-heavy technology designed for experts.
Fortunately, advances in technology are taking away that difficulty. No-code interfaces for MLOps platforms now let non-experts source and process geospatial data with ease.
“That’s why companies like Striveworks exist,” said Foreman, “because end users want to be empowered to make their own models, so they can run custom analyses to achieve their objectives.”
These tools are overcoming the challenges with geospatial analysis and opening up opportunities for organizations to use geospatial data in new ways—without the heavy lifting. In a few clicks, the burden of vast amounts of complex data and scant resources disappears, and organizations across a host of industries can get value from their data like never before.
Do you have challenges in applying geospatial data? Want to learn how Striveworks can overcome those challenges for your organization? Reach out to talk to us today.
