This blog post is part of a series on using large language models for text classification. View the other posts here:
-
Unsupervised Text Classification: Categorize Natural Language With LLMs
-
Text Classification With LLMs: A Roundup of the Best Methods
By Benjamin Nativi, Will Porteous, and Linnea Wolniewicz
Large language models (LLMs) like GPT, which powers Open AI’s ChatGPT, have sparked a revolution. In the words of Striveworks CEO Jim Rebesco, “Everyday experimentation with AI has shifted public opinion from the skeptical ‘Does this work?’ to the declarative ‘This works.’” These deep learning models are incredibly useful for generating new text for a wide range of purposes. Every day, millions of active users rely on LLMs for tasks such as resume writing, topic research, and code debugging. Even more remarkable, users can often achieve impressive results without much customization.
But, while LLMs excel at text generation, the best way to use them for classical natural language processing tasks, like text classification, is less clear. Text classification involves accurately labeling textual data, such as distinguishing spam from important emails. How can users work with LLMs to perform these crucial tasks?
In this blog series, we explore how to use LLMs for text classification. We conducted experiments to determine the best approaches, considerations, and results when working with LLMs for text classification.
Today, our focus is on supervised learning methods for text classification using LLMs (unsupervised learning methods will be covered in an upcoming post). But first, let’s explore the difference between supervised and unsupervised learning for text classification.
Note: For this project, our research focuses on smaller, open-source LLMs like Meta’s Llama, which can be efficiently stored and run on a private server. Unfortunately, while GPT remains popular, it is also bulky and proprietary to OpenAI.
Supervised vs. Unsupervised Approaches to Text Classification
There are various ways to train text classification models, but they typically fall into two broad categories: supervised learning and unsupervised learning.
Supervised learning methods for text classification involve fine-tuning existing models like BERT and BERT-based extensions (e.g., DistilBERT, RoBERTa), as well as using techniques such as Low Rank Adaptation (LoRA) of LLMs and transfer learning. Unsupervised learning methods for text classification, on the other hand, focus on prompt engineering, where an LLM is instructed to classify inputs using constructed prompts without fine-tuning the model. Any user of ChatGPT who has repeatedly reworded the same question already has some experience with prompt engineering.
Both supervised and unsupervised approaches have their advantages. When choosing an approach, the amount of labeled data available for training is a key consideration. Supervised learning requires a larger dataset but can yield highly accurate results in text classification.
What Are the Categories of Supervised Text Classification?
There are three main categories of supervised methods for text classification with LLMs:
- fine-tuned pre-LLM models like BERT
- fine-tuned LLMs via LoRA
- transfer learning
BERT, short for Bidirectional Encoder Representations from Transformers, is a pre-trained encoder model that uses bidirectional attention to encode sequences of text. Bidirectional attention allows BERT to better understand the context of language but is more computationally expensive than the unidirectional attention used by other models. This makes it harder to scale a BERT-like model to the same size as current GPT models.
Before using a pre-trained model like BERT, it must be further fine-tuned on a set of training data to adapt the model to the desired task. For example, if someone wants to determine the popularity of new movies, they can fine-tune BERT on a set of movie reviews from IMDb to get a sentiment analysis model that could analyze the popular opinion of moviegoers.
Before LLMs were introduced in 2020, BERT delivered state-of-the-art performance for text classification on various standard datasets, including the benchmark General Language Understanding Evaluation (GLUE). In our study, we evaluated the performance of DistilRoBERTa, a BERT-like model from Hugging Face with 82 million parameters for text classification.
With the rise of LLMs and their high performance on many tasks, LoRA was introduced as a way to fine-tune them for specific tasks. LLMs learn weights during training that enable them to make accurate suggestions. LoRA works by freezing the weights of a pre-trained model and injecting trainable rank decomposition matrices into each layer of the LLM’s transformer. These matrices allow users to fine-tune LLMs for specific tasks while reducing the number of trainable parameters significantly (a factor of ~1,000). LLMs fine-tuned through LoRA perform exceptionally well.
The final supervised method we evaluated for text classification is transfer learning. Transfer learning involves reusing knowledge learned from one task to enhance performance on a related task—for example, using information gained by classifying images of cars to classify images of trucks.
In our research, we applied transfer learning to a pre-trained Llama model to generate hidden states for each token in an input sequence. Typically, each word in a sentence is considered a token by the LLM, although some longer words get split into multiple tokens, such as “researching” being split into “research” and “-ing.” Each token is assigned a hidden state by the LLM, and the hidden state can change depending on the surrounding tokens. Through transfer learning, the hidden state of the final token in a sequence is passed to a classification head—a layer added to the end of a pre-trained LLM for classification purposes. This classification head performs a series of functions on the hidden state to predict the final label. (Specifically, the classification head is trained to take the hidden state of dimension 4096 and output a logit of dimension k, where k is the number of labels. This logit is then passed through softmax and argmax to determine the final label. See Figure 1.)
The benefit of this transfer learning scheme is a significant reduction in training load. Instead of training a model with 7 billion parameters or more, users only need to train a single classification layer with approximately 25,000 parameters. Additionally, for a given dataset, the hidden states only need to be computed once and can be cached to train the classification head. The training paradigm is visualized in the figure below.
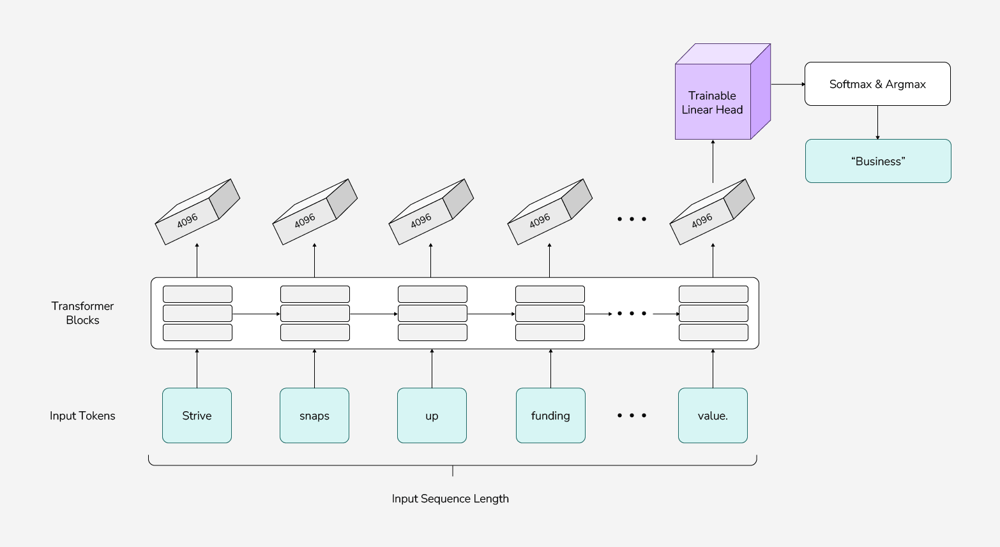
Figure 1: This diagram shows the inference process when using the Llama model to perform text classification. With transfer learning, the linear head is updated during training. For LoRA fine-tuning, the transformer blocks are updated during training.
Comparing Performance of Supervised Methods
To compare the performance of the supervised methods, we can look at their macro F1 scores on the Text REtrieval Conference (TREC) Question Classification dataset. This score is a common metric for evaluating performance of classification models; the TREC dataset is an open-source dataset often used for text classification.
The TREC dataset categorizes questions based on the type of answer being requested, such as abbreviation, entity, description and abstract concept, human being, location, and numeric value. The abbreviation class contains questions like “What does S.O.S. stand for?,” the entity class contains questions like “What was the first domesticated bird?,” and so on.
We applied all three methods of text classification to the TREC dataset and evaluated their F1 scores. As expected, with sufficient data, all three methods achieved high results. However, the interesting aspect is the performance of different methods at different training sizes.
The LoRA fine-tuned Llama-7b model consistently performed the best across all training sizes (Figure 2). Meanwhile, the pre-LLM DistilRoBERTa model initially had poor performance until trained on most of the training set. The Llama-7b transfer learned classification head showed better performance than the pre-LLM model but worse performance than LoRA fine-tuning. (All methods’ macro F1 scores were compared on the same test set of 512 examples to examine the relationship of each model with its training data.)
While Llama-7b fine-tuned with LoRA demonstrates the most consistent performance, it should be noted that the computational cost of training each of these models varies widely. Figure 3 shows the training cost versus performance for each of the approaches at the 512 train size.
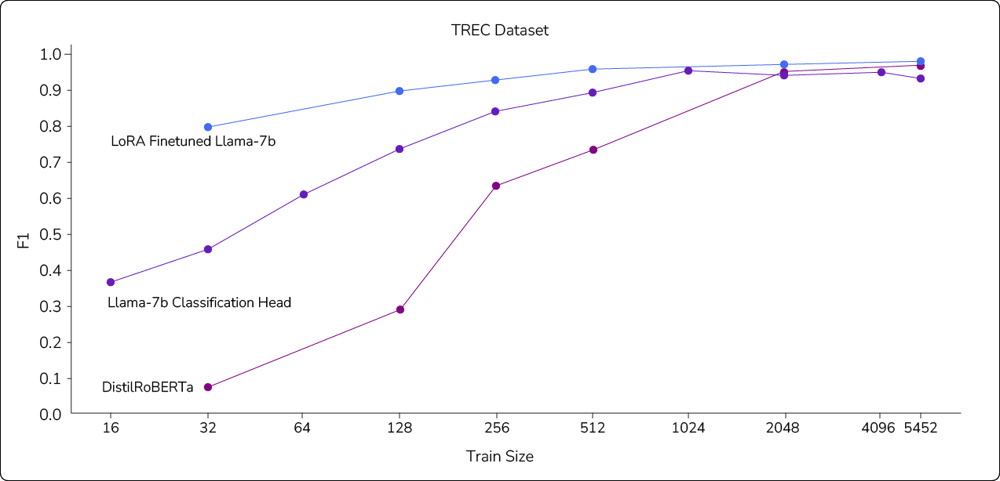
Figure 2: This chart shows the relative performance of the three supervised learning methods we tested for text classification. As shown, LoRA performed quite well on the TREC dataset, even with a small number of examples. DistilRoBERTa, on the other hand, required significantly more data to achieve similar performance.
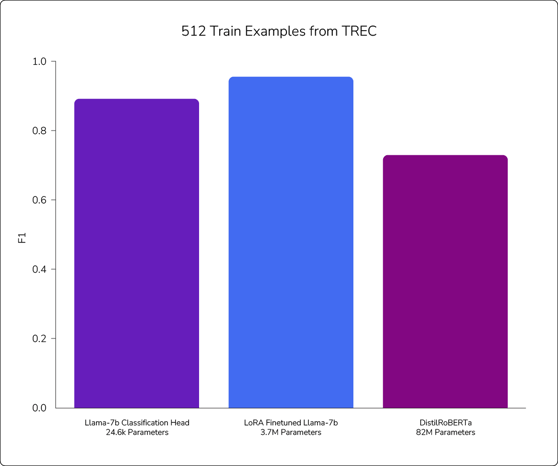
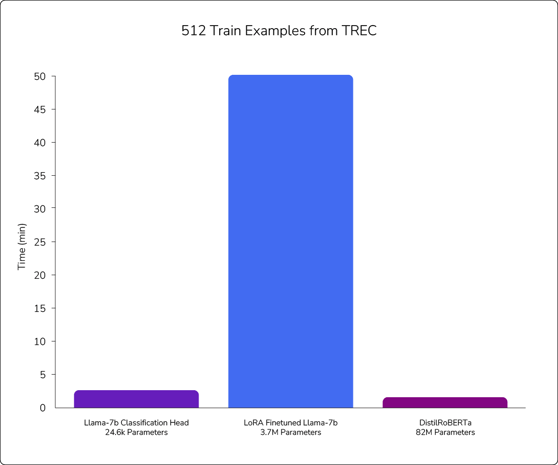
Figure 3: These charts show the performance of the supervised learning methods in relation to the amount of time required. As shown, LoRA performed best but required significantly more time to train. Conversely, the transfer learning method (Llama-7b Classification Head) performed almost as well but involved much less computation time and power.
As we can see in Figure 3, LoRA achieved the highest F1 at a specific training size of 512 data points while the Llama sequence head performed slightly worse, and DistilRoBERTa performed much worse. However, LoRA takes much longer to train than the other two methods.
For both DistilRoBERTa and LoRA, points from the dataset are repeatedly passed through the model, and changes are backpropagated to update the model weights. Even though LoRA has fewer weights to update than DistilRoBERTa, the 7 billion parameter Llama model is much larger, resulting in longer forward passes.
With the classification head, each training point can be passed through the model just once, storing the final hidden states. Then, the much smaller classification head can be trained by repeatedly passing the hidden states through it. This process is much faster: In our experiment, we were able to cache the 512 hidden states for the train set, train up to 300 epochs, and perform testing in only 2.65 minutes.
This speed gives the classification head method a huge advantage over LoRA, as LoRA requires each point to pass through the entire model for each epoch of training. The only reason why the classification head takes slightly longer than training DistilRoBERTa is that the initial forward pass through Llama does take a significant amount of time. The computation with the classification head is frontloaded whereas DistilRoBERTa takes the same amount of time on each epoch.
Although a fine-tuned BERT-based model is performant with access to a large amount of labeled data, we found that both LoRA and the classification head approaches offered significant advantages when access to data was limited. With enough computing power, LoRA fine-tuning with Llama was by far the highest performing strategy. However, if access to compute is restricted, then transfer learning with a single-layer classification head offers significant performance gains without an increase in computation.
BERT vs. LoRA vs. Transfer Learning
Our research has shown a clear advantage to fine-tuning LLMs to use them for text classification. While BERT and BERT-like models delivered state-of-the-art results a few years ago, LLMs perform significantly better. Specifically, LoRA provides remarkable accuracy for text classification—although at the cost of substantial computational resources. A more efficient alternative is transfer learning using a single-layer classification head, which still maintains strong classification capabilities with much less overhead.
But supervised learning is only one option for text classification with LLMs. Unsupervised learning through prompt engineering has emerged as a viable alternative. How well do LLMs perform text classification when guided only by a natural language prompt? Can this approach compete with the results from supervised learning? We explore these questions and more in the next post in our series. Stay tuned!
Want to know the Striveworks vision for text classification with LLMs? Reach out to schedule a conversation today.
References
- Jacob Devlin et al., “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” (2019): *arXiv preprint arXiv:1810.04805*.
- Edward J. Hu et al. “LoRA: Low-Rank Adaptation of Large Language Models,” (2021), *arXiv preprint arXiv:2106.09685*.
- Alex Wang et al., “GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding,” (2019): *arXiv preprint arXiv:1804.07461*.
